March 18, 2025
BlogResearchTranslator: Broad Protein Annotation, Fast
Translator predicts structured protein annotations from amino acid sequence, helping researchers triage function, tune precision and recall, and decide which sequences deserve deeper review.
- Annotation Vocabulary
- Protein Function
- Atlas
By Logan Hallee
The Problem: Unknown Proteins Need More Than Sequence Search
Protein sequences arrive faster than they can be curated. Metagenomic datasets, designed proteins, newly sequenced organisms, and variant libraries can all produce candidates with sparse or incomplete functional annotation.
Sequence similarity is useful, but it is not always enough. A sequence can be distant from known proteins, carry multiple functional hints, or need a structured first pass before a human decides where to look next.
Translator was built for that first pass.
The Core Idea
Translator maps an amino acid sequence into structured annotation hypotheses from the Annotation Vocabulary framework.
Instead of producing loose prose, it returns terms that can be inspected, filtered, and compared across proteins. The model can surface enzyme functions, Gene Ontology-style terms, domains, cofactors, UniProt-style keywords, and related functional signals.
The key distinction is that Translator does not certify function. It organizes plausible annotation hypotheses so researchers can prioritize review.
Precision, Recall, and Control
Translator exposes controls that let users tune the output for a conservative or exploratory workflow.
top_k controls how many annotations are retrieved per prediction step. Lower values tend to be more conservative. Higher values can improve recall, but they also bring in more uncertain annotations.
confidence controls the minimum score required for an annotation to appear in the output. Raising the threshold makes the result set smaller and more conservative. Lowering it makes the result more exploratory.
In the evaluation shown below, top_k=3 provided the best F1 tradeoff in the reported evaluation sets. The same analysis also identified confidence thresholds where every annotation above the threshold was correctly predicted in that setting.
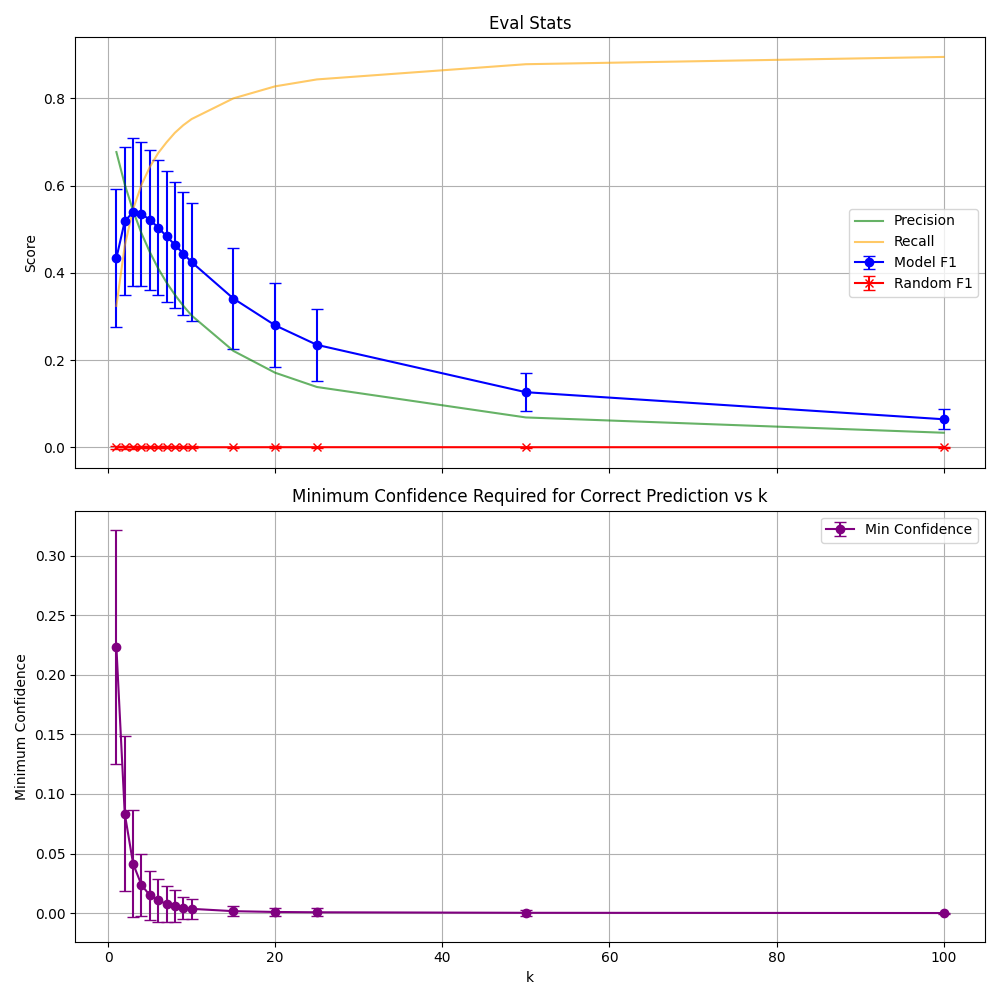
Figure 1: Translator calibration across top_k and confidence settings on unseen evaluation data.
Use It Now
Translator is callable as a public independent API endpoint with a Synthyra API key:
import requests
api_key = "..." # synthyra.com/settings?section=api-keys
resp = requests.post(
"https://api.synthyra.com/v1/translator/run",
headers={"Authorization": f"Bearer {api_key}"},
json={
"sequences": ["MEV..."],
"ids": ["random_seq"],
"num_annotations": 32,
"top_k": 3,
},
timeout=180,
)
for ann in resp.json()["results"][0]["annotations"]:
print(f"[{ann['aspect']}] {ann['name']} ({ann['confidence']})")
Pricing in the current source content is $0.002 per sequence. See the API docs for the full inventory.
Why This Matters
Translator is useful when a team has too many sequences for manual annotation and too much uncertainty for blind automation.
It can help triage metagenomic hits, generated proteins, enzyme candidates, and unfamiliar proteins before deeper database review, structure analysis, or wet-lab work. It also connects naturally to Atlas because functional annotations make interaction and ligand hypotheses easier to interpret.
The output is not experimental truth. It is a structured starting point for deciding what to inspect next.
Limitations
Translator can miss rare activities, over-prioritize common annotations, or confuse related functional families. Its predictions should be checked against curated resources, sequence search, structural evidence, literature, and experimental validation when the decision matters.
Related Research
July 30, 2024
BlogAnnotation Vocabulary: Teaching Protein Models the Language of Function
Annotation Vocabulary turns protein properties into a structured language, giving models a cleaner bridge between sequence, function, and design.
- Annotation Vocabulary
- Protein Function
- Atlas
October 10, 2025
BlogAtlas: Making Protein Screens Searchable
Atlas turns sequence-first protein models into searchable maps for interaction, ligand, and annotation work.
- Atlas
- Protein Protein Interaction
- Drug Discovery
- Protein Function