August 21, 2025
BlogResearchProtify: Model Choice As An Experiment
Protify is a low-code platform for comparing protein language models under shared data handling, probing, transfer learning, and reporting protocols.
- Protify
- Benchmarking
- Protein Language Models
By Logan Hallee
Protein language models are not interchangeable. ESM2, ESMC, E1, ProtTrans, Ankh, DPLM, DSM, GLM2, SaProt, and related models all produce useful representations, but they do not fail or succeed in the same places.
That makes model choice an empirical question. A model that works well for variant effect prediction may not be the best choice for enzyme classification, localization, solubility, protein-protein interaction, or sparse Gene Ontology labels.
Protify exists because the field still makes many of those comparisons by stitching together one-off scripts.
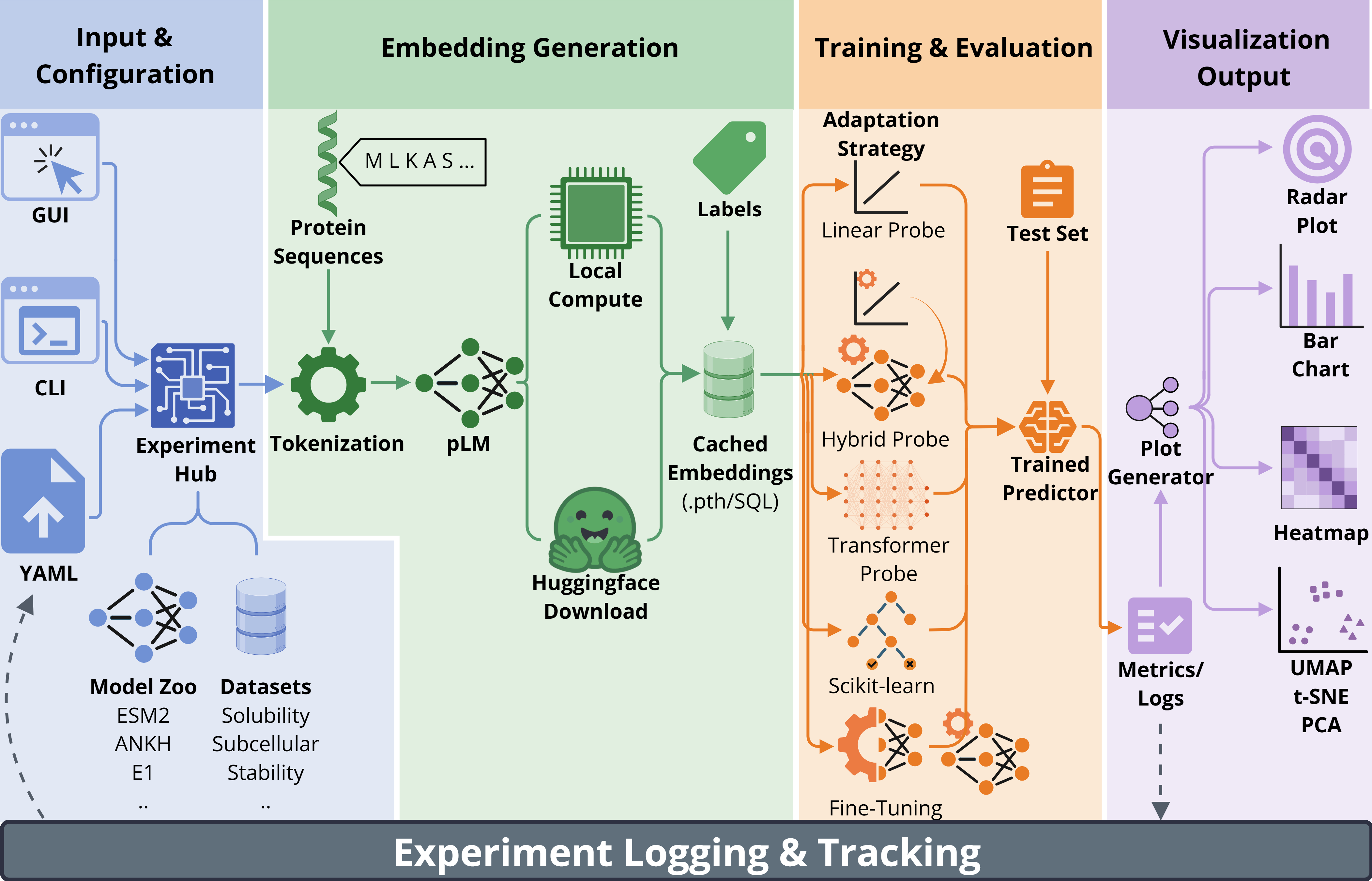
What Protify Standardizes
The Protify manuscript describes an open-source, low-code framework for protein model evaluation. The point is not to hide the modeling work. The point is to make common comparisons easier to run under shared assumptions.
Protify handles model loading, embedding extraction, dataset loading, supervised probes, transfer-learning workflows, scikit-learn pipelines, experiment logging, and visualization. In the manuscript version, it supports 34 pretrained models and 59 curated datasets across enzyme classification, Gene Ontology annotation, PPI, localization, stability, and related protein property tasks.
That structure matters because small differences in preprocessing, pooling, splitting, metrics, or probe architecture can change the story a benchmark appears to tell.
What The Benchmark Shows
One result from the paper is worth keeping close: there is no universal winner.
Protify benchmarks 23 models on ProteinGym substitutions and runs a supervised vector benchmark across 32 protein tasks. In the supervised benchmark, 13 different models achieve the top score on at least one dataset. That is the more useful conclusion than a single leaderboard rank.
The zero-shot ProteinGym analysis also shows how quickly rankings can shift by model family and protocol. In the manuscript, DPLM-3B is the top semi-supervised encoder in that comparison, with average Spearman correlation of 0.421, while several large or newer models do not dominate uniformly.
The practical lesson is not "always use model X." It is "test the model on the task you actually care about."
Adaptation Is A Trade-Off
The paper also compares adaptation strategies on sparse multi-label annotation tasks. Linear probes are often stronger than they sound because a lot of useful signal is already present in frozen embeddings. LoRA can be worth the extra cost when the task needs representation movement but full finetuning is too expensive or too easy to overfit.
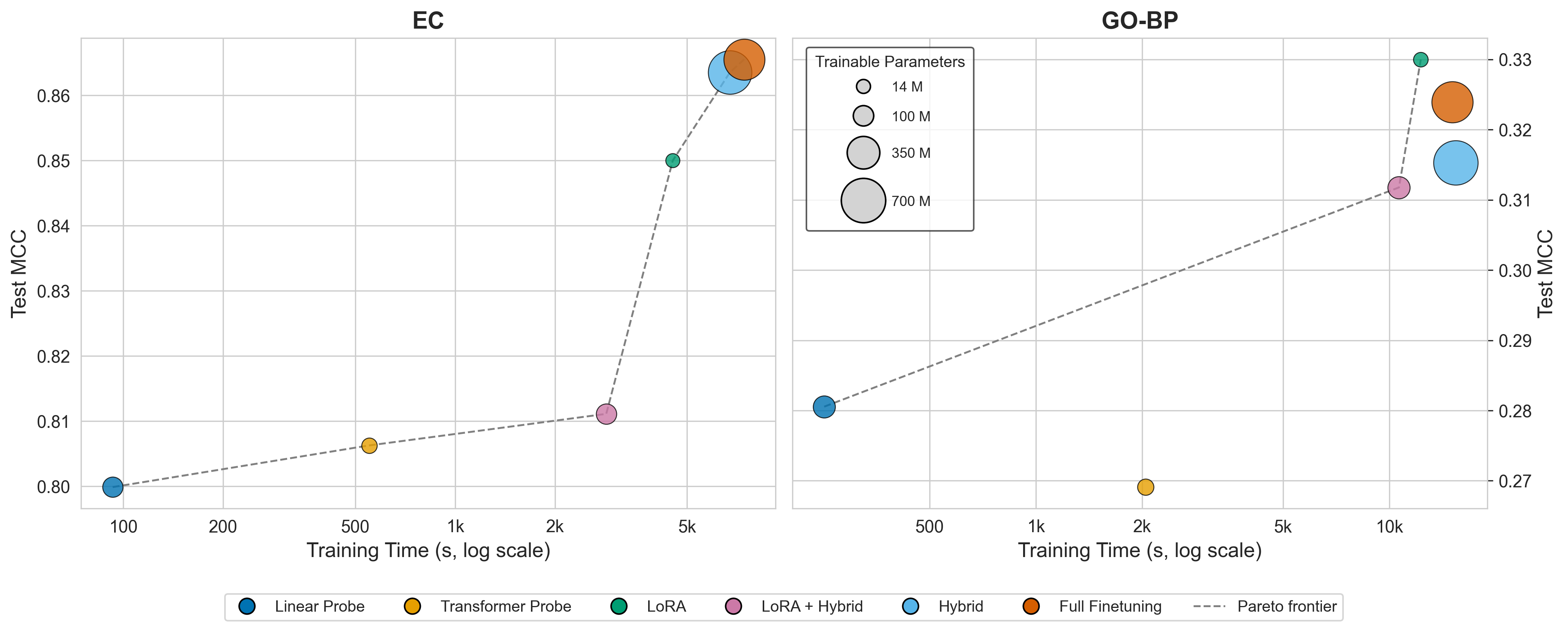
The Pareto result is the part I like most: the efficient methods are not just toy baselines. Linear probes and LoRA sit on the useful frontier in the case studies, while heavier methods only justify themselves when the gain is worth the compute and complexity.
Protify also keeps a path open for GPU-free workflows. The scikit-learn case study is not pretending that classical models solve every protein problem. It shows that embeddings can still be useful in resource-constrained settings, especially when the goal is fast triage or a first reproducible baseline.
How This Connects To Synthyra
Protify is part of the research habit behind Synthyra: choose models by controlled evidence, not by parameter count or release date.
That habit matters for products like Atlas and Discover because each biological task has its own failure modes. Some tasks are homology-sensitive. Some are taxonomy-sensitive. Some need long context. Some need residue-level information. Some are mostly solved by a frozen representation and a small probe.
Protify gives us a way to ask those questions repeatedly instead of rebuilding evaluation infrastructure every time.
Limitations
Protify makes evaluation easier, but it does not make a dataset unbiased. Results still depend on label quality, split design, homology control, metric choice, assay relevance, and whether the benchmark actually matches the intended use.
That is the right level of ambition. Protify does not answer every protein modeling question. It makes the question easier to ask cleanly.
This blog post summarizes work in the following paper:
Protify: A low-code protein property prediction platform
Nikolaos Rafailidis, Logan Hallee, Tamar Peleg, Colin Horger, Luck Haviland, Jason P. Gleghorn
Manuscript draft, August 2025
Related Research
September 15, 2023
BlogcdsBERT: Why Codons Still Matter for Protein AI
cdsBERT showed that protein models can learn useful biology by looking one layer earlier, at the codons that encode amino acids.
- Codons
- Protein Language Models
- Foundation Models
April 9, 2026
BlogDual Triangle Attention: Position Sense for Bidirectional Models
Dual Triangle Attention keeps bidirectional context while giving transformers a built-in directional signal.
- Attention
- Transformers
- Foundation Models