October 24, 2025
BlogResearchAccidental Taxonomists: When Protein Models Learn the Wrong Shortcut
Accidental Taxonomists shows how random negatives in multi-species PPI datasets can create a taxonomy shortcut, and why same-species negative sampling is a necessary control.
- Protein Protein Interaction
- Dataset Curation
- Atlas
By Logan Hallee
Protein-protein interaction models are usually trained to answer a biological question: are these two proteins likely to interact?
In multi-species datasets, they can accidentally get an easier question: did these two proteins come from the same species?
That is the Accidental Taxonomists problem. Protein language model embeddings carry phylogenetic information. If the labels in a PPI dataset are correlated with taxonomy, a model can perform well without learning much interaction biology.
The Shortcut
Most curated PPI databases are positive-first. They tell us which protein pairs have been observed to interact, but they rarely contain experimentally established negatives. A common workaround is to generate negatives by randomly pairing proteins that are not known to interact.
That sounds reasonable until species enters the picture.
In BioGRID, the paper finds that 96.5 percent of positive PPI pairs are intra-species. Randomly shuffled negatives are intra-species only 31.8 percent of the time. This means a classifier that detects "same species" can get surprisingly far.
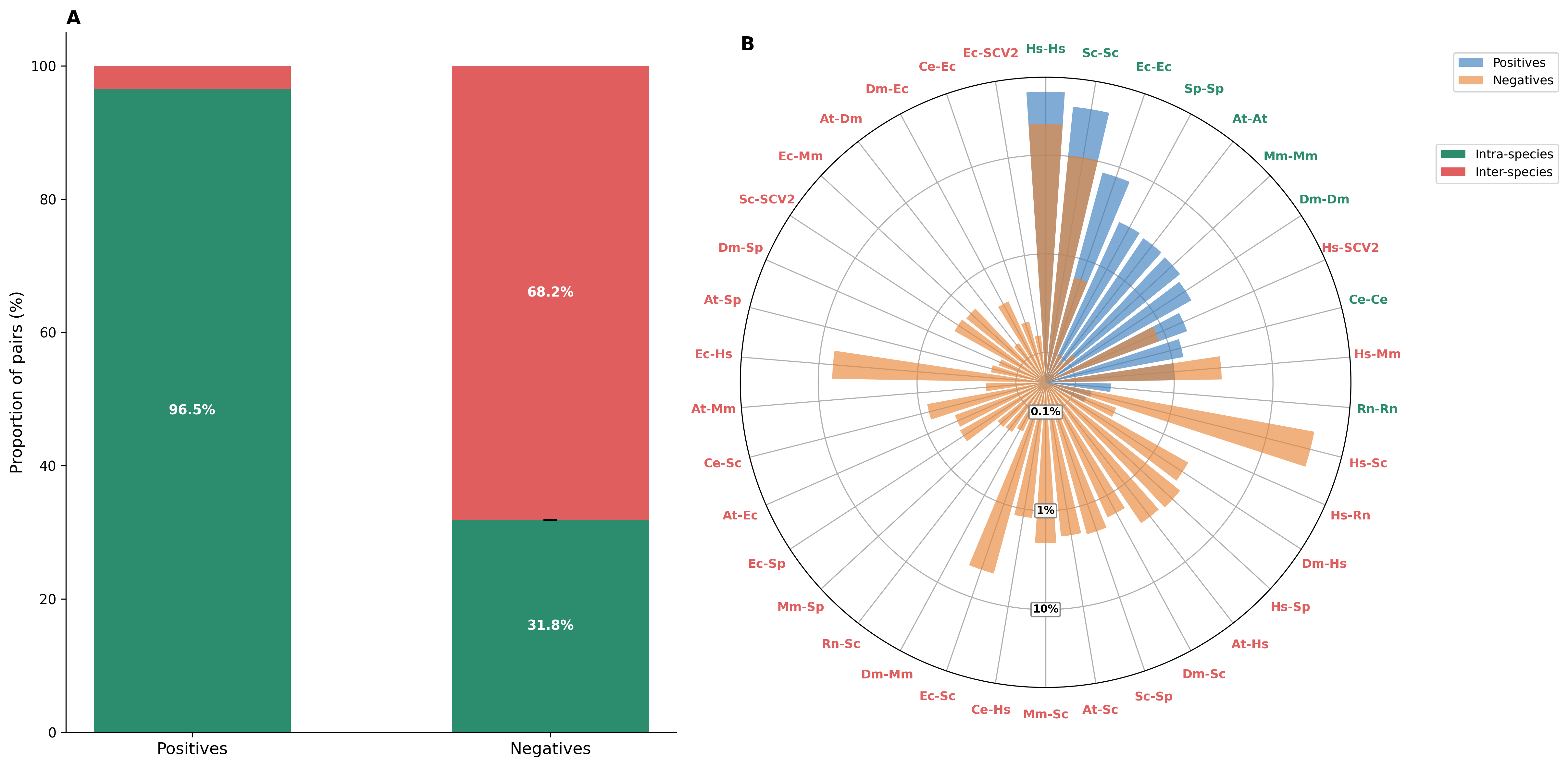
The supplementary simulation makes the shortcut concrete. A perfect taxonomic classifier, using only the intra-species vs inter-species pattern, would reach AUROC 0.822 and PR AUC 0.745 on a balanced BioGRID-like dataset without learning interaction features.
The Model Can See It
The next question is whether pLM embeddings actually contain enough taxonomy signal to exploit the shortcut.
They do. In the manuscript, probes trained on pLM embeddings can distinguish taxonomic origin across multiple levels. The most relevant task is paired binary discrimination: given two sequences, decide whether they are from the same species. That mirrors the input structure of PPI prediction. ESMC-600M embeddings reach F1 of 0.87 on this same-vs-different species task.
So the confound is not hypothetical. The model has access to the shortcut.
Same-Species Negatives
The fix is simple in principle: when constructing negative examples, sample them from the same species as the positive pair.
The paper compares normal sampling, where negatives are randomly drawn across the whole multi-species dataset, with strategic sampling, where negatives are constrained to the same species. Normal sampling looks much better on its matched validation set, with average MCC around 0.71. But on a shared same-species test set, it drops to about 0.23 MCC. The strategically sampled model holds up better, around 0.34 MCC.
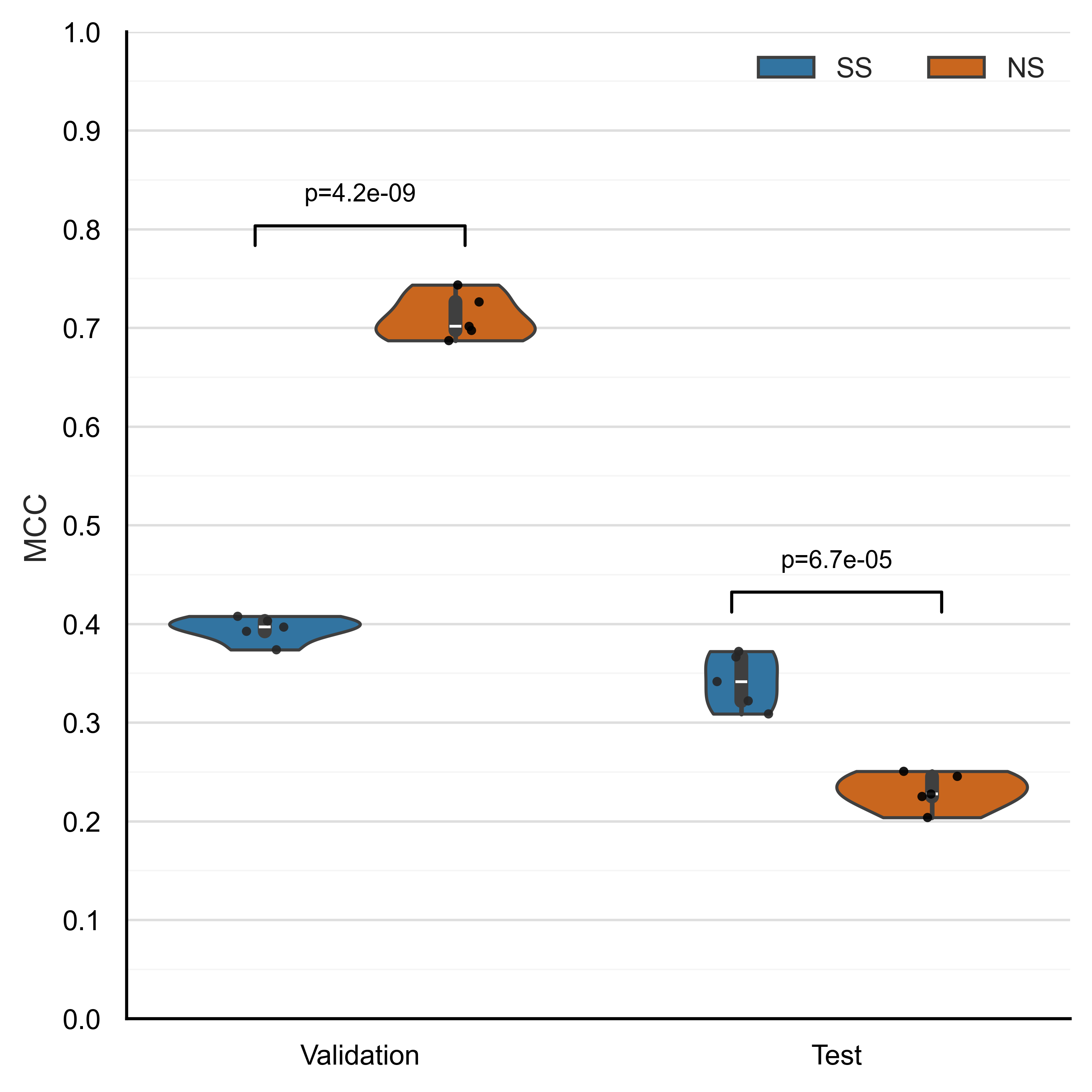
That drop is the result. The model trained on normal negatives had learned a real signal, but too much of that signal was taxonomy.
Why This Matters For Atlas
Atlas depends on sequence-based interaction prediction. If a model wins by learning dataset construction, its interaction maps become less useful for biology.
Same-species negatives, homology-aware splits, and cluster-aware evaluation make the task harder in the right way. They ask whether the model can still rank plausible interactions when the easiest species-level shortcut is removed.
This is also why a model description should not only discuss architecture. The data design is part of the model's behavior.
The General Lesson
The Accidental Taxonomist problem is clearest in PPI, but the pattern is broader.
Any supervised protein dataset can contain hidden correlations between labels and taxonomy, organism source, assay source, curation practice, or sequence redundancy. EC prediction, localization, stability, phenotype labels, and regression tasks can all carry unwanted structure if one taxonomic region dominates a label.
The practical rule is direct: if taxonomy could explain the label, control for taxonomy.
For Atlas users, this means interaction scores are built from a more skeptical training and evaluation culture. They still need experimental validation. They are just less likely to be a species detector wearing an interaction-model name tag.
This blog post summarizes work in the following paper:
Protein Language Models are Accidental Taxonomists
Logan Hallee, Tamar Peleg, Nikolaos Rafailidis, Jason P. Gleghorn
Manuscript draft, October 2025
Related Research
October 10, 2025
BlogAtlas: Making Protein Screens Searchable
Atlas turns sequence-first protein models into searchable maps for interaction, ligand, and annotation work.
- Atlas
- Protein Protein Interaction
- Drug Discovery
- Protein Function
September 18, 2025
BlogSynteract-4: Interaction Prediction as Retrieval
Synteract-4 reframes protein-protein interaction prediction as sequence-only representation learning at proteome scale.
- Protein Protein Interaction
- Synteract
- Atlas